Or at least come to Boulder and have a beer. The FRUGOS (Front Range Users Group of GIS Open Source?) folks are meeting at the Boulder Beer Company tomorrow night. More info. I’m thinking of attending, but the Boulder Denver New Tech Meetup is happening at the same time in a different place, so I’m torn.
All posts by moore - 72. page
IP Crash Course Slides Available
A few weeks ago, Jason Haislmaier posted the slides that I referenced. (The audio is still unavailable.)
Two of my favorite slides are below (click to see them in all their Powerpointy glory).

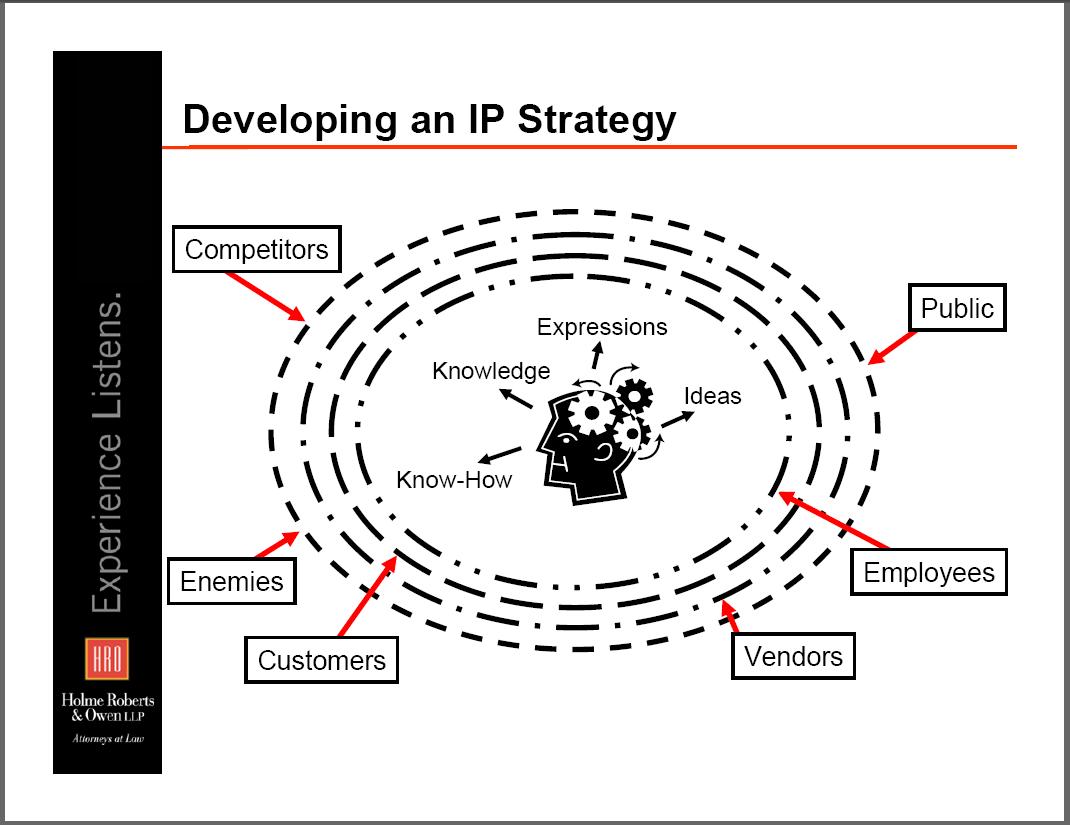
But there are plenty of other good ones, so take a look if the topic interests you.
[tags]intellectual property,presentations[/tags]
My experience at the MySQL Performance Coding Webinar
Last Tuesday, I attended a MySQL webinar. I registered on the MySQL website (with a site-specific email address, of course) and periodically am invited to these webinars. I’d tried to attend in the past, but something else (usually billable) always interfered. Not this time!
The talk was titled “Performance Coding for MySQL” and the author, Jay Pipes, did a fantastic job. (He is also the co-author of Pro MySQL.) The slides from the presentation are up, and he also answered questions sent to him during the presentation in some detail as well. His presentation, about an hour in length, covered both basics (like, normalize first (slide 4), think in sets rather than iterators (slides 20-23)–basic, but not intuitive), and under the hood intricacies (like, think about the size of your primary keys and consider record size (slide 6), avoiding deletes with MyISAM (slide 27) and vertical partitioning to take advantage of the query cache (slides 9-11) ) . He also pointed to a script that he wrote to find useless indices.
Well worth my time. Thanks MySQL and Jay, for making a resource like this available and free! There’s a whole lot more, so I’d recommend downloading the slides and giving them a run through, if you interact with MySQL as a DBA or a developer (or, as is often the case, both).
(On that note, I’d like to recommend the MySQL DBA blog for your perusal–apparently recently renamed the ‘Senior MySQL DBA’ blog, heh.)
[tags]mysql dba, think in sets, webinar[/tags]
Author of ‘Ask the Headhunter’ now blogging
The author of my favorite jobs/careers newsletter, Ask The Headhunter, is now blogging. In his first post, Nick says he’ll consider some of the following questions:
Why does HR dump jobs into the Monster pit? How can managers recruit without resumes? Do all headhunters really suck? How can you get past the Top 10 Stupid Interview Questions? Is there a way to get a raise without begging?
And he starts right off with an explanation of why job hunters shouldn’t focus on the macro economy job stats.
If you haven’t checked out his site, it’s well worth a read as well, especially the articles. Of course, he writes with a bias (he is a head hunter, after all), but I find his tone humorous and his advice accurate (where I’ve applied it).
IP Crash Course For Entrepreneurs
This past Wednesday, I went to an interesting talk sponsored by Silicon Flatirons (an organization worth knowing about). Jason Haislmaier gave the talk, and the subject was intellectual property (IP); it was titled ‘Intellectual Property “Crash Course” for Entrepreneurs’ and was packed! I got there 10 minutes late (parking on the CU campus is no fun at all) and sat in the back on a heater. Good thing the fire department didn’t come by, as I’m sure we were over capacity. (Incidentally, I heard about this via the Boulder Denver New Tech Meetup mailing list but it was also on the Colorado Startups Events calendar.)
Jason said the presentation and possibly a recording of it would be available, but I was unable to find it by looking around his blog or the Silicon Flatirons site. I took some notes, but his presentation, if and when it becomes available, will be a great introduction to what entrepreneurs need to know about IP. (Note that all mistakes herein are mine, and I am most definitely not a lawyer. Consult your friendly attorney for serious advice. I marked things I thought I remembered with a ‘?’.)
There are 4 kinds of IP: patents, which are ideas or inventions, trademarks, which are about branding, copyright, which deals with creative expression, and trade secrets, which is know how. The overall emphasis on his talk was that you may not need protection from one or any of these forms of property, but that you, as an entrepreneur should be aware of all of them and make a conscious choice to pursue or not to pursue them. Which makes a lot of sense to me! (Incidentally, he repeatedly mentioned that the US was different in IP than the rest of the world, in a lot of ways, so if you plan to do business internationally, you should definitely think about that sooner rather than later.)
Trade secrets are pretty much anything–data, methods, software, etc. The protection is dependent on keeping them secret. Jason was working with a $10-20 million company that had only one patent; its valuation was almost entirely based on trade secrets. NDAs and employment contracts are the front line of trade secrets. He emphasized that you need to read NDAs and think about how they affect you and your relationship with the NDA signer. In particular, you can’t expect a signer to forget everything they’ve learned after a relationship ends, but you can expect them to return all the tangible forms of information. NDAs should have remedies (injunctions). If the other side won’t sign an NDA, that’s fine, just don’t tell them anything that you wouldn’t want to see posted on the Internet.
Copyright is protection for an original work or authorship in a tangible form from which the work can be perceived, not an idea. Apparently, there was a famous case (Feist) which basically outlined the limits of copyright–anything more creative than the White Pages qualifies for copyright protection. There are five rights, which I didn’t note because I thought the presentation would be up. Copyright can be unregistered (just about anything–these notes and this blog post are unregistered copyright) or registered. Registering costs something, but means you can sue folks. Under the DMCA, the copyright owner no longer has to show infringement–the possibility of infringement is enough (?). There are safe harbors though, one of which is the service provider harbor(?). You have to register with the Library of Congress and take things down if notified, but if you are providing any service with user generated content, you should pursue this safe harbor.
Trademarks (or service marks) are about branding. They’re easier to file for than patents. Use in commerce generates rights. He had a great slide showing the protection levels of trademarks from the fantastic (Kodak, Exxon) to the arbitrary (Apple) to the suggestive to the descriptive (World Poker Tour) to the generic (aspirin, escalator). The more the trademark describes what it represents, the less protectable it is, and trademarks can be lost (as escalator was).
Patents–the big one! Patents are the right to excludes others from making, using and selling a new, useful and non-obvious invention. There are a number of reasons to patent–defensive, offensive, ego, source of revenue (a secondary market is developing for patents. Offensive patents are getting riskier recently (courts are narrowing down patent infringement). But, investors are starting to ask why patents weren’t filed, and “we didn’t think to do so” is a poor answer. The answer to the question “Is it patentable?” for almost any value of “it” is yes, but you need to think about why–the better question is “How relevant and valuable will a patent be for the business?”. Lack of knowledge or independent development is not a defense against patent infringement.
All in all, it was a lot of ground to cover. Jason did a good job making things very applicable to the audience he was talking to. It kinda sucks that you have to think about such things, when all you want to do is develop killer software. (Brian made an offhand comment about patents and long running servlets almost 4 years ago, incidentally.) As Jason said in closing, if you don’t have an intellectual property strategy, your competitors will give you one (and, I inferred, you probably won’t like that one very much).
GWT Talk at the Boulder Denver New Tech Meetup tonight
I presented on the Google Web Toolkit at the Boulder Denver New Tech Meetup tonight (presentation and useful links). It was a rush, as presentations always are. However, the adrenaline was compounded by two factors: the length of the presentation and the composition of the audience.
To present something as large in scope as GWT in 5 minutes was difficult. Though I’d been to 3 previous meetups, I didn’t have a good feel for the technical knowledge of the audience, so I aimed to keep the presentation high level. (The audience, on this particular night, was about 50/50 split between coders and non coders, as determined by a show of hands. However, almost everyone knew the acronym AJAX and what it meant.) This lack of knowledge compounded the difficulty, but I still feel I got across some of the benefits of GWT.
I’ll be writing more about what I learned about GWT in preparing for this, but I wanted to answer 3 questions posed to me that I didn’t have off the cuff answers for tonight.
1. Who is using GWT?
I looked and couldn’t find a good list. This list is the best I could do, along with this GWT Groups post. I find it rather astonishing that there’s not a better list out there, as the above list was missing some big ones (Timepedia’s Chronoscope, the Lombardi Blueprint system) as well as my own client: Colorado HomeFinder.
2. How much time does the compilation process add?
I guessed on this tonight but guessed too high. I said it was on the order of 30 seconds to a minute. On my laptop (2 cpu/2 ghz/2 gb of ram box) GWT compilation takes ~7 seconds to build incrementally (from ant, which appears to add ~2 seconds to all of these numbers) and ~21 seconds to build after all classes and artifacts have been deleted. This is for 7400 lines of code.
3. How does GWT compare to other frameworks like Dojo and YUI?
I punted on this one when perhaps I should not have. From what I can tell, GWT attacks adding dynamic behavior to web pages in a fundamentally different way. Dojo and YUI (from what I know of them) are about adding behavior to existing widgets on a page. GWT is about adding objects to a page, which may or may not be attached to existing widgets. I’ll not say more, as I don’t have the experience with other toolkits to speak authoritatively.
Also, here’s an AJAX toolkit comparison that I found.
[tags]gwt presentations, unanswered questions[/tags]
BatchUpdateException using Hibernate and MySQL5
I ran into a crazy error last week. One of my clients was upgrading from MySQL4 to MySQL5. The application in question was using Hibernate 3.2. Here’s the table structure, and the hibernate bean definition. See if you can spot the issue:
mysql> desc stat; +--------------+-------------+------+-----+---------------------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-------------+------+-----+---------------------+-------+ | stat_date | date | | PRI | 0000-00-00 | | | stat_type | varchar(50) | | PRI | | | | stat_count | int(11) | YES | | NULL | | | last_updated | datetime | | | 0000-00-00 00:00:00 | | +--------------+-------------+------+-----+---------------------+-------+ 4 rows in set (0.00 sec) <class name="com.foo.common.data.Statistic" table="stat" lazy="false"> <cache usage="read-write"/> <composite-id name="statisticId" class="com.foo.common.data.StatisticId"> <key-property name="date" type="java.util.Date" column="stat_date"/> <key-property name="type" column="stat_type"/> </composite-id> <property name="count" column="stat_count"/> <property name="lastUpdated" type="java.util.Date" column="last_updated" /> </class>
The exception stack trace I was seeing was something like this:
2007-12-31 14:15:09,888 ERROR [Thread-14] def.AbstractFlushingEventListener (AbstractFlushingEventListener.java:301) - Could not synchronize database state with session org.hibernate.exception.ConstraintViolationException: Could not execute JDBC batch update at org.hibernate.exception.SQLStateConverter.convert(SQLStateConverter.java:71) at org.hibernate.exception.JDBCExceptionHelper.convert(JDBCExceptionHelper.java:43) at org.hibernate.jdbc.AbstractBatcher.executeBatch(AbstractBatcher.java:249) at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:235) at org.hibernate.engine.ActionQueue.executeActions(ActionQueue.java:139) at org.hibernate.event.def.AbstractFlushingEventListener.performExecutions(AbstractFlushingEventListener.java:298) at org.hibernate.event.def.DefaultFlushEventListener.onFlush(DefaultFlushEventListener.java:27) .... Caused by: java.sql.BatchUpdateException: Duplicate key or integrity constraint violation message from server: "Duplicate entry '2007-12-31-stattype' for key 1" at com.mysql.jdbc.PreparedStatement.executeBatch(PreparedStatement.java:1492) at com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeBatch(NewProxyPreparedStatement.java:1723) at org.hibernate.jdbc.BatchingBatcher.doExecuteBatch(BatchingBatcher.java:48) at org.hibernate.jdbc.AbstractBatcher.executeBatch(AbstractBatcher.java:242) ... 57 more
I ended up turning on the mysql logging (the log setting in the my.ini file, which logs all sql statements mysql makes) to see what was happening.
Basically, I was looking to see if an entry in the stat table existed; if it did, increment and update, if it did not, insert. And the insert was always happening, so the entry was not found--it did exist because mysql threw the 'integrity constraint' exception.
The cause of the issue was the date type of stat_date and the fact that I incorrectly mapped it to java.util.Date. It really should have been mapped to java.sql.Date. How this worked in mysql4 is beyond me, but it did. Changing the hibernate dialect to mysql5 had no impact.
[tags]mysql upgrade,hibernate[/tags]
GWT Mini Pattern: Cache ‘static’ data
Using the Java marshalling API makes remote calls from GWT to a Java server quick and easy. However, each of those calls introduces performance and complexity issues. Performance, because browsers tend to limit the number of remote network calls per server. From the HTTP 1.1 RFC: “A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy.” This means that if you have more than two components making network calls, the calls will queue up (and that ignores image downloads and other network connections). The complexity arises from the non linear nature of asynchronous network calls. This can lead to a program structure that is not easily understood without careful reading (‘first, we find the user, then, after that we branch, and if we have a valid user, we find their saved bookmarks from the server…’).
If you have an amount of static content that doesn’t often change from user to user, use a RequestBuilder to retrieve the data from the server. Whatever software generates the data should set headers such that the page is cached for a fair while (either via the Cache Control header or the Expires header). The first time the request is made, the browser ends up making a network request–all the way to the server. After that, the browser will return the resource from its cache, using fewer network resources and returning the data more quickly. Using this approach also makes data available across components and pages. I almost always use JSON to represent such rarely changing data, because GWT can parse that easily, though you could use some other data format as well.
Using the browser as your caching system is not free: you pay for the creating of the network call (XMLHttpRequest, etc) and the reparse of the JSON. But you aren’t going over the network, and it’s relatively transparent to all the clients. The alternative, however, of creating your own caching system, is often more daunting–especially if you want to share data across page requests. I’m not aware of any caching systems (such as ehcache) that are GWT compatible at the moment (and they’d have their own costs in terms of javascript download size). Google Gears does provide something compatible, but is not transparent to the user (Gears requires installation).
[tags]caching, gwt, leverage the browser[/tags]
Video: Here Comes Another Bubble
From the Richter Scales, on Youtube. (Sorry, I didn’t bother to take the time to get the plugin to embed youtube videos.)
[tags]funny ha ha, tech bubble,newspapers + friendship bracelets[/tags]
GWT Mini Pattern: Configuration Reader
I’ve written about configuration options to GWT widgets before. Basically, the idea is that you have some configuration that lets the widget change behavior without redeploying or compiling code. In fact, nontechnical users (like designers) can change configuration, if it’s documented. These are the ways I know to specify configuration:
Meta tags
In the page:
<meta content="bar" name="foo" id="foo" />
Updated 4/1/2008, to have id in the meta tag attbute.
In your code:
String var = DOM.getElementProperty(DOM.getElementById("foo"), "content");
You can also request only Boolean and Int:
String var = DOM.getElementPropertyInt(DOM.getElementById("foo"), "content");
This is simple, all browsers ignore these tags, and you can place them anywhere in a page and get them read. However, attributes can only contain strings.
Hidden spans
In the page:
<span id="foo" style="display: none">bar</span>
In your code:
String var = DOM.getInnerHTML(DOM.getElementById("foo"));
This is a good choice if you want configuration to be more structured than what a tag attribute can provide--you can parse the 'var' string further.
Javascript using jsni
<script type="text/javascript"> var ID = 'bar'; </script>
And in your code:
private native String getIDAsString()/*-{
if ($wnd.ID == undefined) {
return "";
} else {
return $wnd.ID;
}
}-*/;
private Integer getID() {
Integer id = new Integer(-1);
try {
id = Integer.valueOf(getIDAsString());
} catch (NumberFormatException ignore) {}
return id;
}
Integer foo = getID();
This method is great when you have variables that are used by other javascript components that you'd like to leverage for your GWT component, or if you have a really complex configuration that is multiple levels in structure.
Javascript using dictionary
(As outlined here and here.)
In the page:
<script type="text/javascript">
var dictionary = {
foo: "bar"
};
</script>
In your code:
Dictionary theme = Dictionary.getDictionary("dictionary");
String bar = theme.get("foo");
This is good for simple hash datastructures. I haven't tried it, but from the documentation, it doesn't look like it supports anything past String key value pairs, and your module must inherit from com.google.gwt.i18n.I18N.
Regardless of your configuration method, I've found myself using a ConfigReader to isolate this logic. It looks something like this:
public class ConfigReader{
private final boolean opt1;
private final String opt2;
public ConfigReader(){
// init opt1 and opt2 using one of the four methods above.
}
public boolean isOpt1() {
return opt1;
}
public String getOpt2() {
return opt2;
}
}
