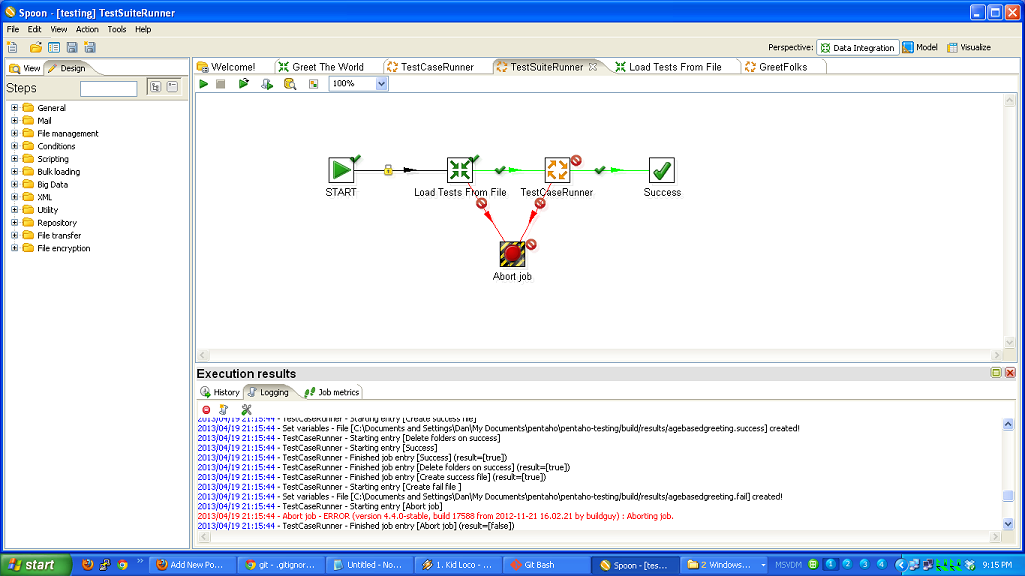
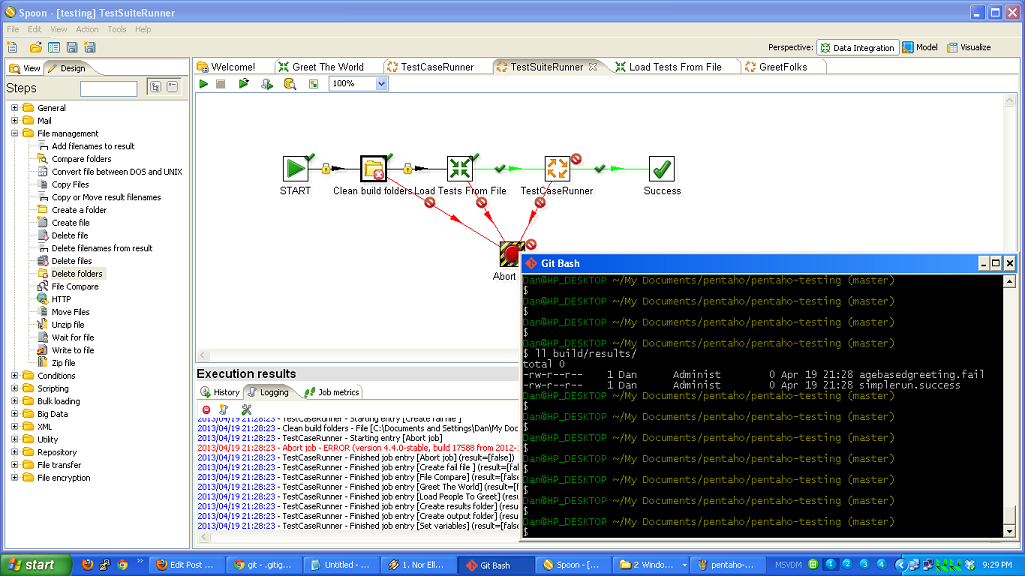
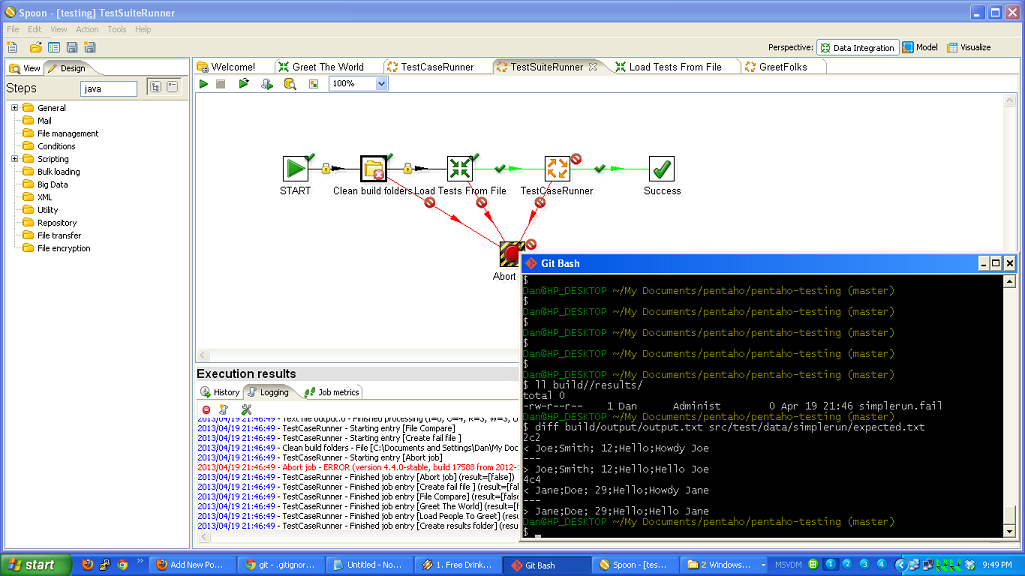
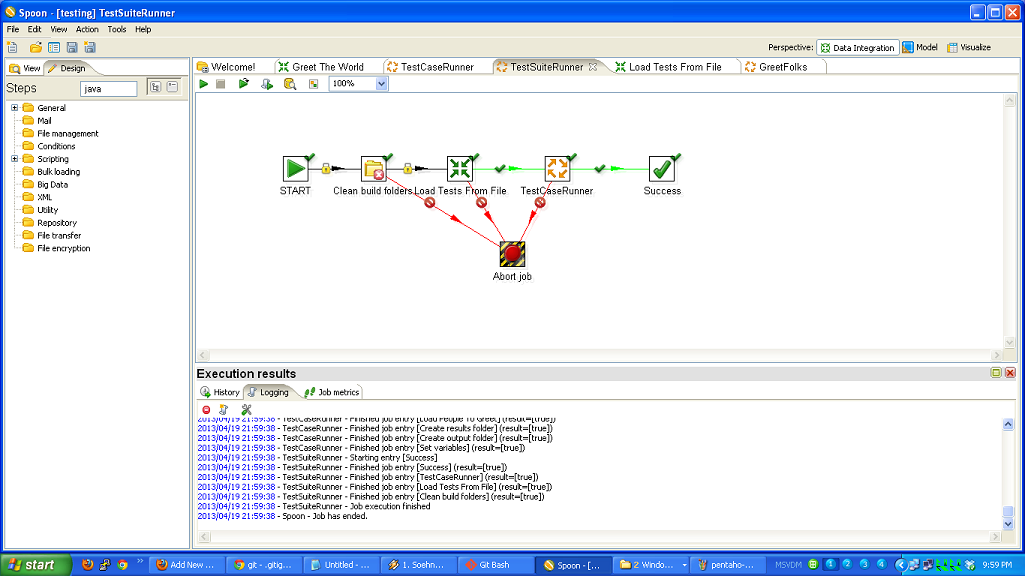
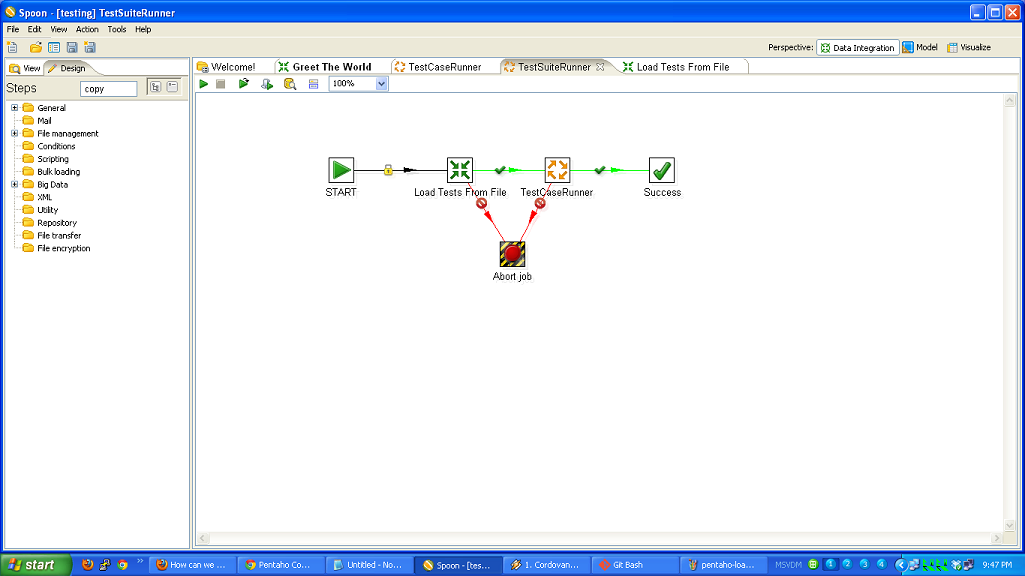
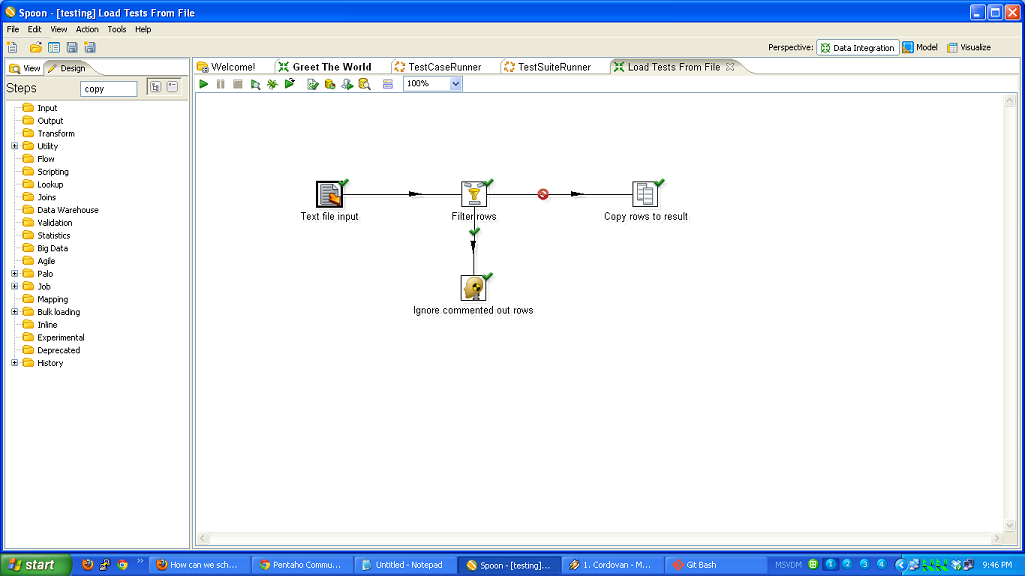
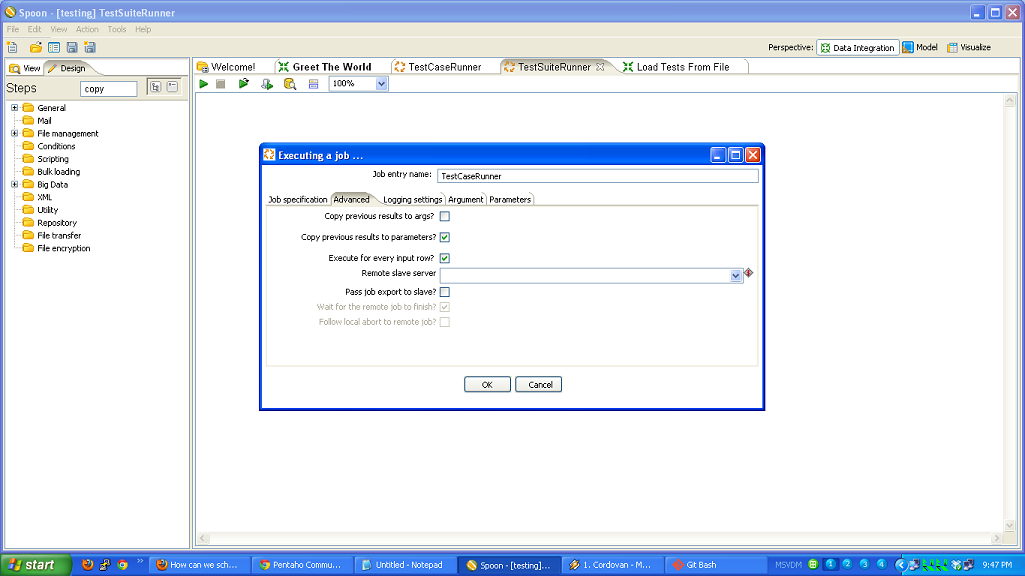
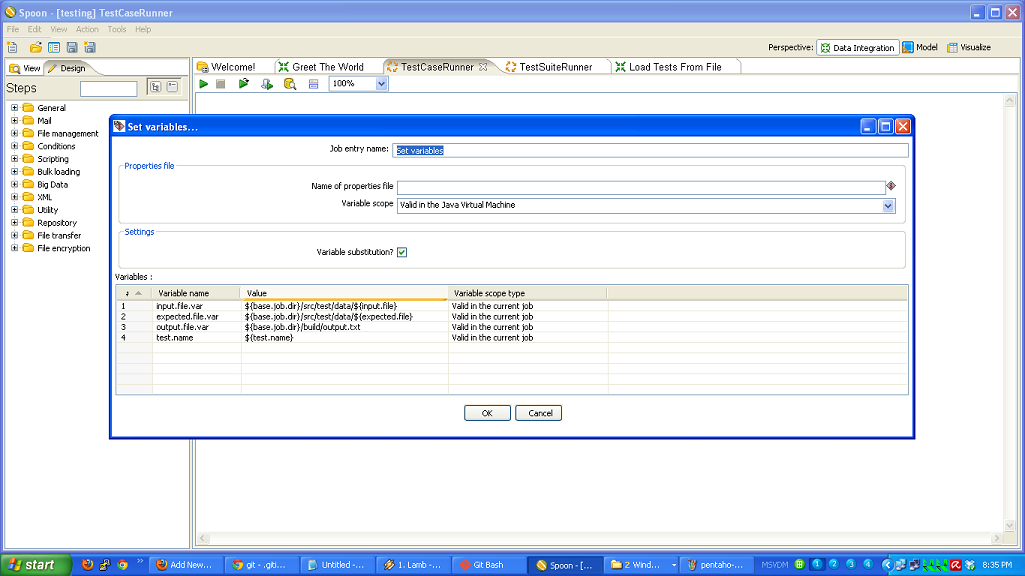
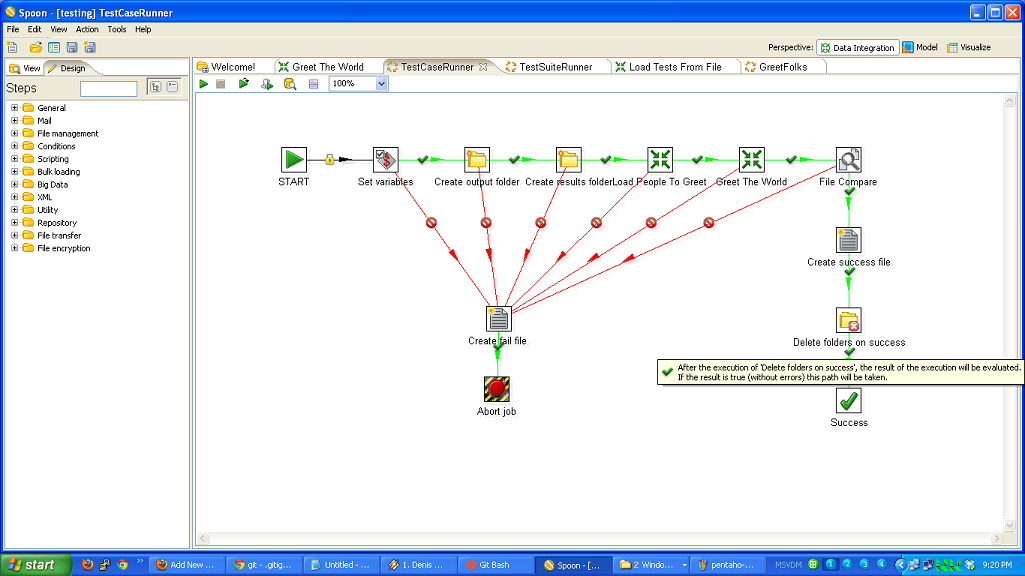
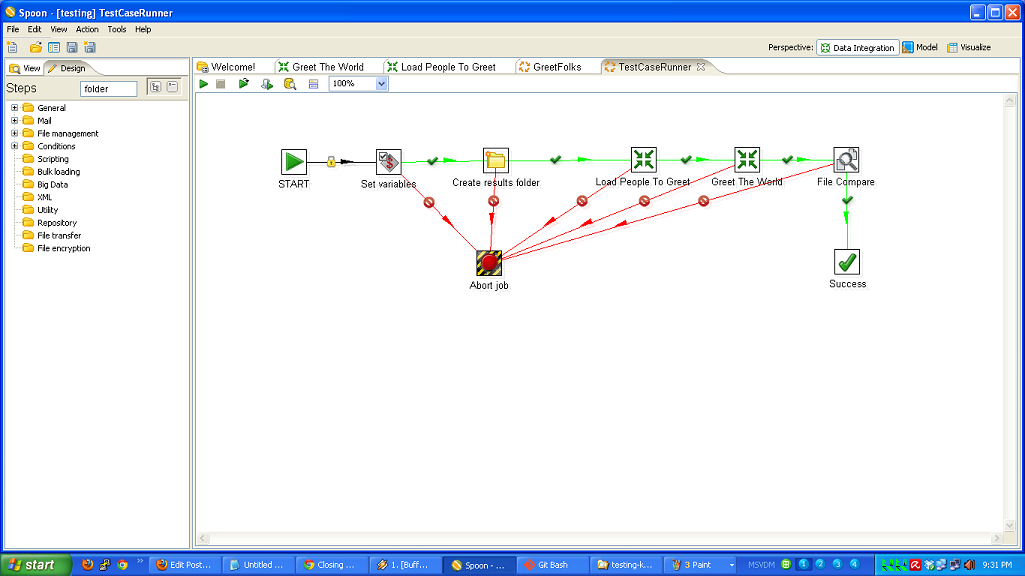
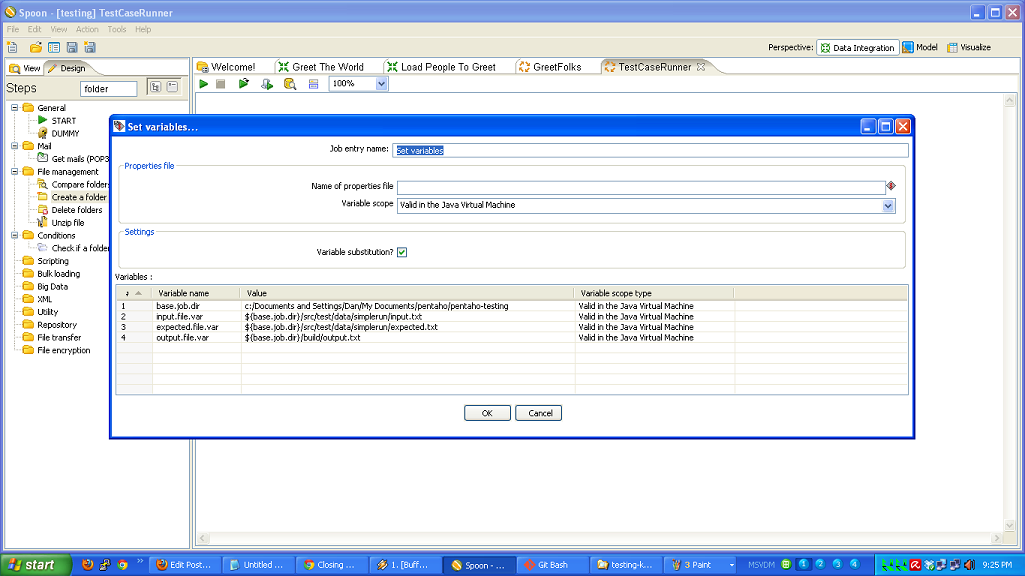
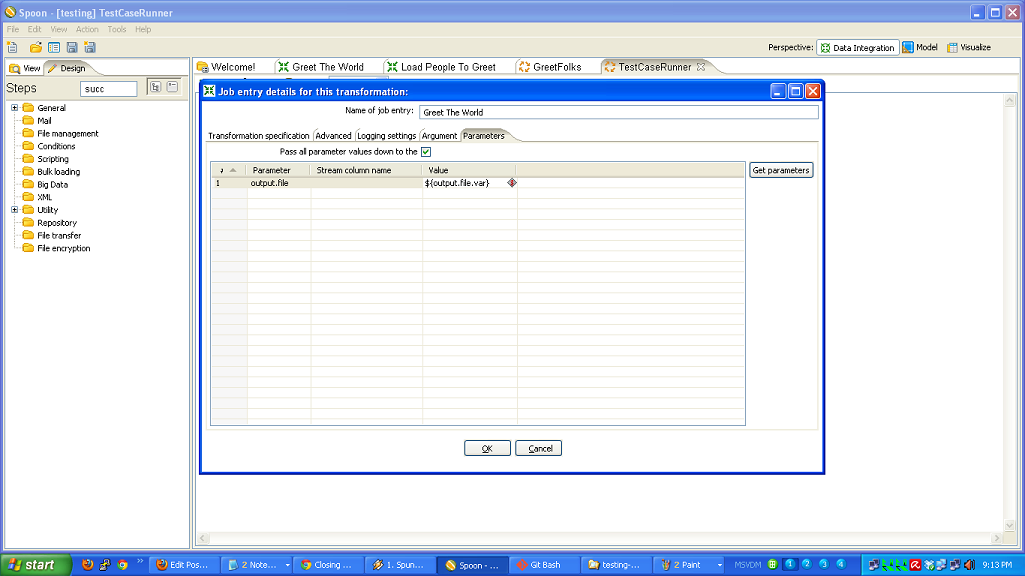
So, to review, we’ve taken a (very simple) ETL process and written the basic logic, constructed a test case harness around it, built a test suite harness around that test case, and added some logic and a new test case to the suite. In normal development, you’d continue on, adding more and more test cases and then adding to your core logic to make those test cases pass.
This is the last in a series of blog posts on testing Pentaho Kettle ETL transformations. Past posts include:
- The benefits of automated testing for ETL jobs
- what parts of ETL processes to test
- current options and frameworks for testing Kettle
- writing testable business logic
- running one test using TestCaseRunner
- running multiple tests using TestSuiteRunner
- adding a test for new logic
Here are some other production ready ETL testing framework enhancements.
- use database tables instead of text files for your output steps (both regular and golden), if the main process will be writing to a database.
- run the tests using kitchen instead of spoon, using ant or whatever build system is best for your operation
- integrate with a continuous integration system like hudson or jenkins to be aware when changes break the system
- mock up external resources like database tables and web services calls
If you are interested in setting up a test of your ETL processes, here are some tips:
- use a file based repository, and version your kettle files. Being XML, job and transformation files don’t handle diffs well, but a file based repository is still far easier to version than in the database. You may want to try an XML aware diff tool to help with versioning difficultties.
- let your testing infrastructure grow with your code–don’t try to write your entire harness in a big upfront effort.
By the way, testing isn’t cost free. I went over some of the benefits in this post, but it’s worth examining the costs. They include:
- additional time to build the harness
- hassle when you add fields to the output, because you have to go back and add them to all the test data as well
- additional thought required to decide what to test
- running the tests takes time (I have about 35 tests in one of my kettle projects and it can take about 10 minutes to run them all)
However, I still think, for any ETL project of decent size (more than one transformation) or that will be around for a while (any time long enough to evolve), an automated testing approach makes sense.
Unless you can guarantee that business requirements won’t change (and I have news for you, you can’t!), testing can give you the ability to explore data changes and the confidence to make logic changes.
Happy testing!
Signup for my infrequent emails about pentaho testing.