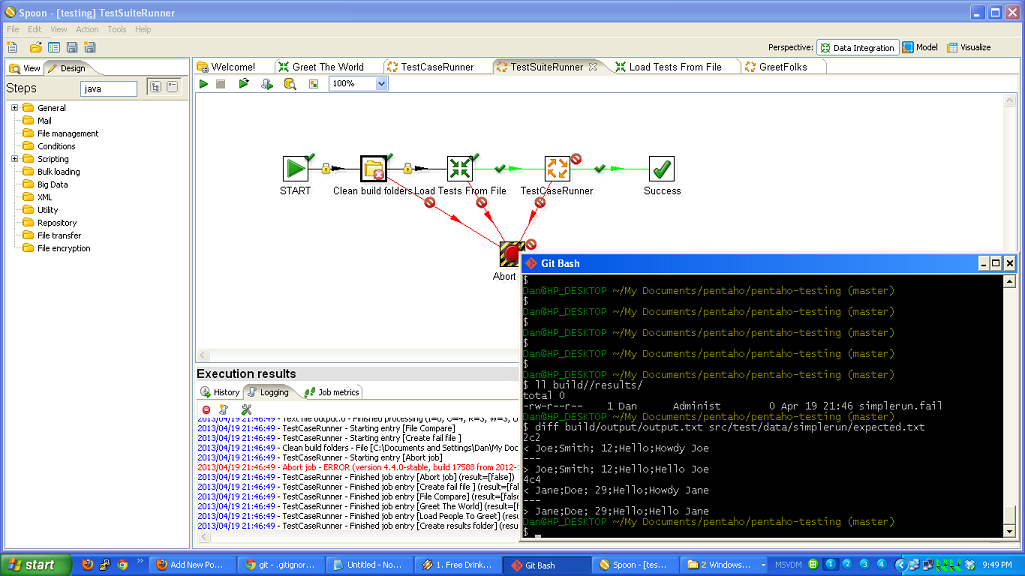
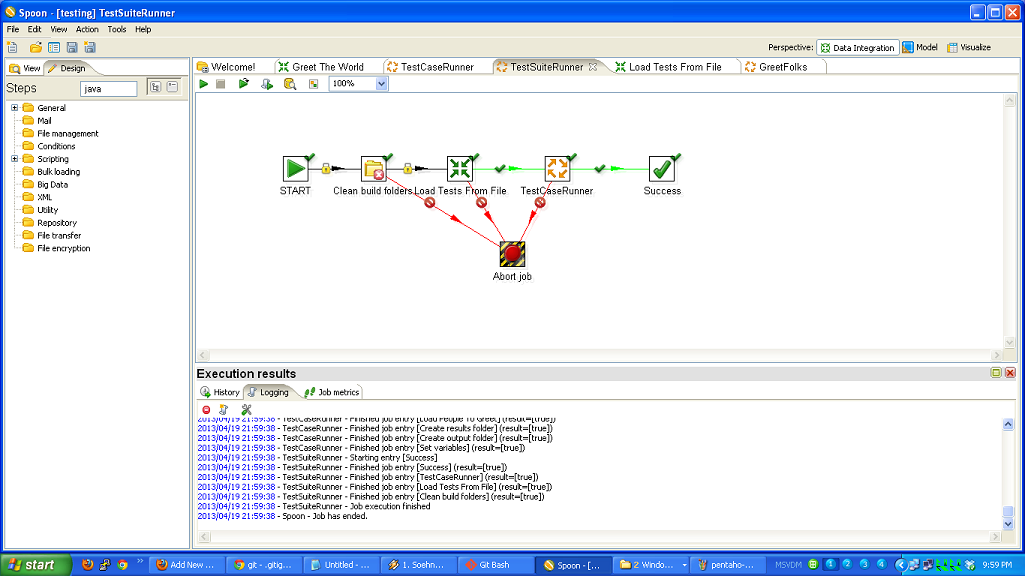
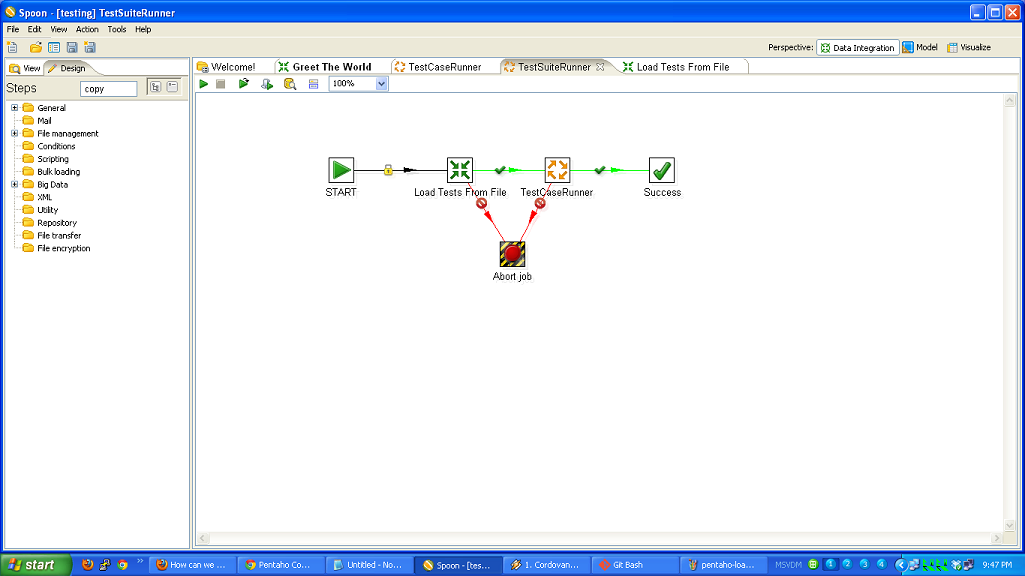
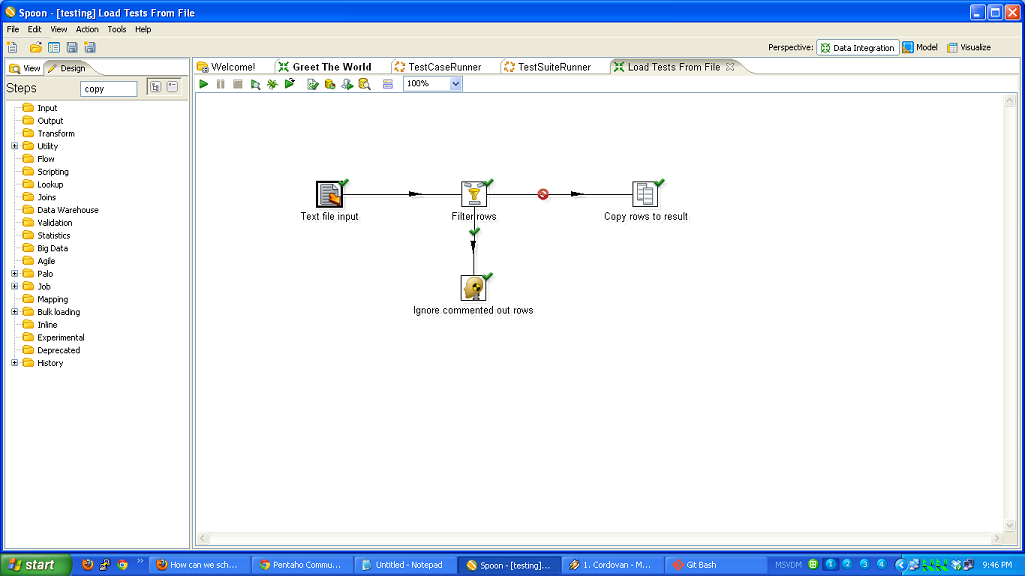
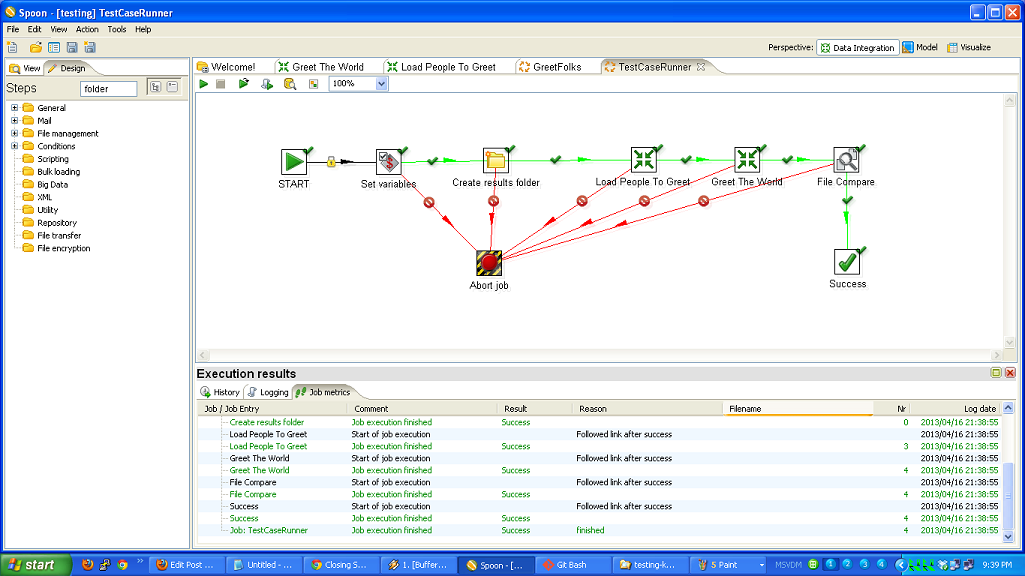
I’m a big fan of ETL tools. The one with which I am most familiar is Kettle, aka Pentaho Data Integration. When I was working for 8z, we used it heavily to pull data from other systems, process it, and update our databases. While ETL systems are not without their flaws, I think their strengths are such that everyone who is moving data around should consider them. This is more true now than in the past because there is a lot more data flowing everywhere, and there are several viable open source ETL tools, so you don’t have to spend thousands or tens of thousands of dollars to get started.
What are the benefits of ETL tools?
- There are pre-built components for common data tasks (connecting to a database, parsing a flat file) that have been tested and debugged by many many people. It’s hard to over emphasize how much time this can save, allowing you to focus on business logic.
- You operate at a higher level of abstraction.
- There is support for other performance features like parallel jobs that you can configure.
- The GUI makes data flow obvious.
- You can write your own components that leverage existing libraries.
What are the detriments?
- Possible to version control, impossible to merge.
- Limits of components mean you sometimes have to contort your data flows, or drop down to write your own component.
- Some components (at least for Kettle) are not open source.
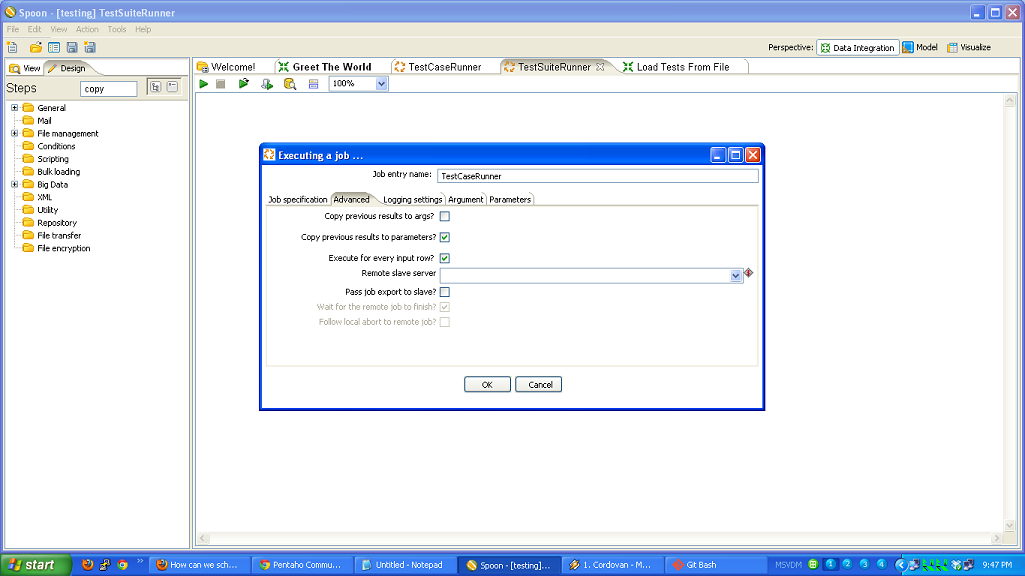
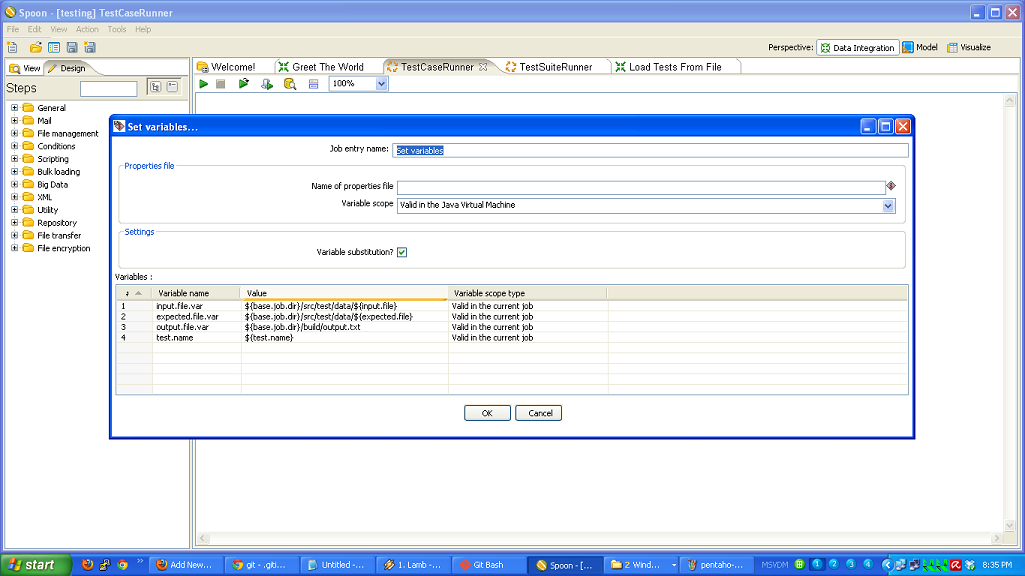
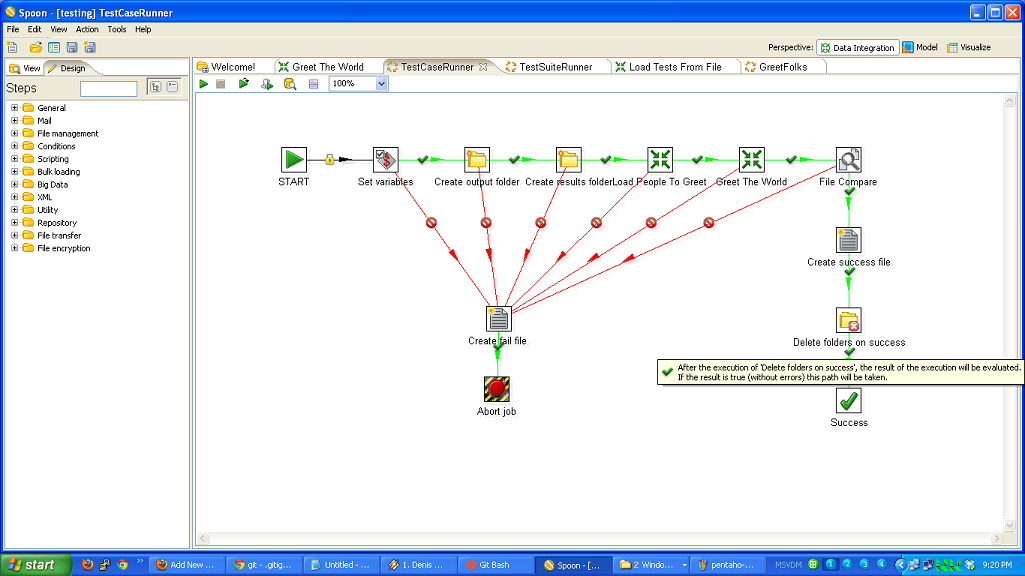
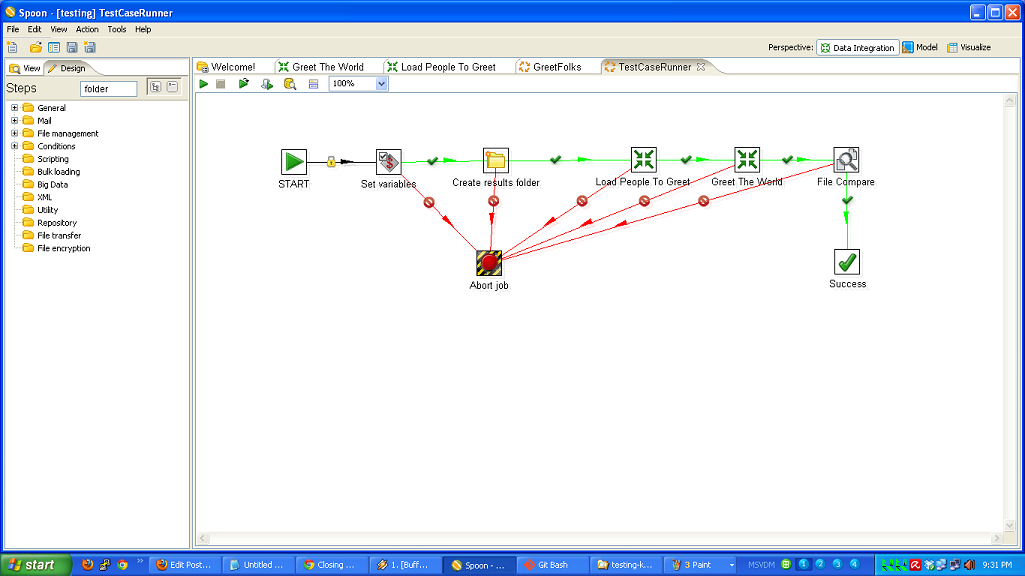
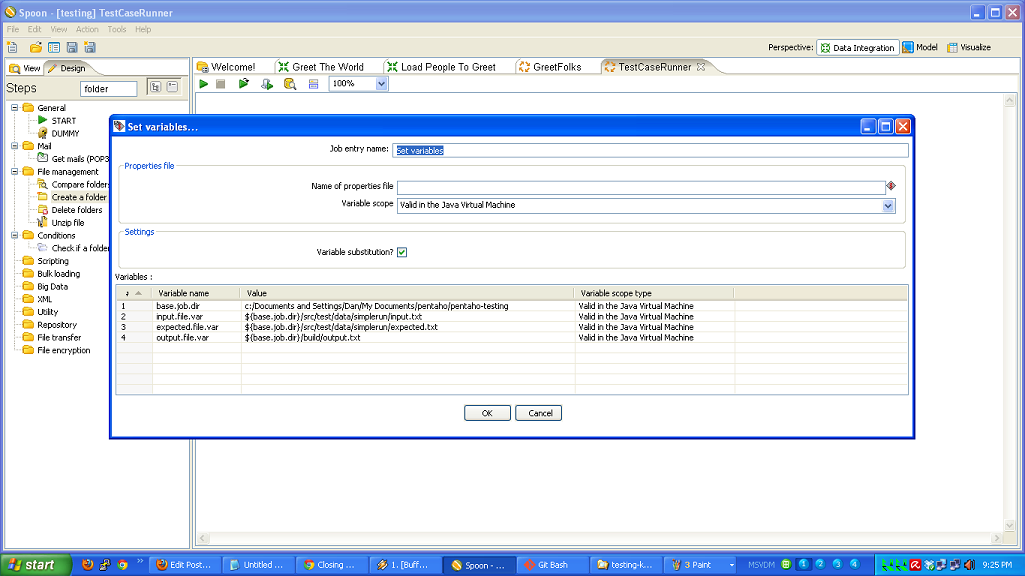
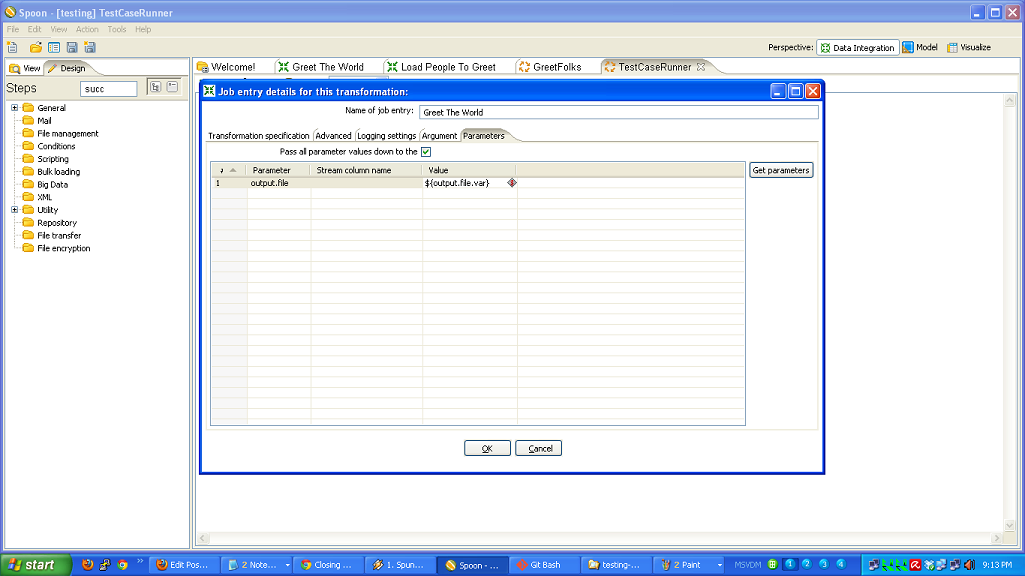
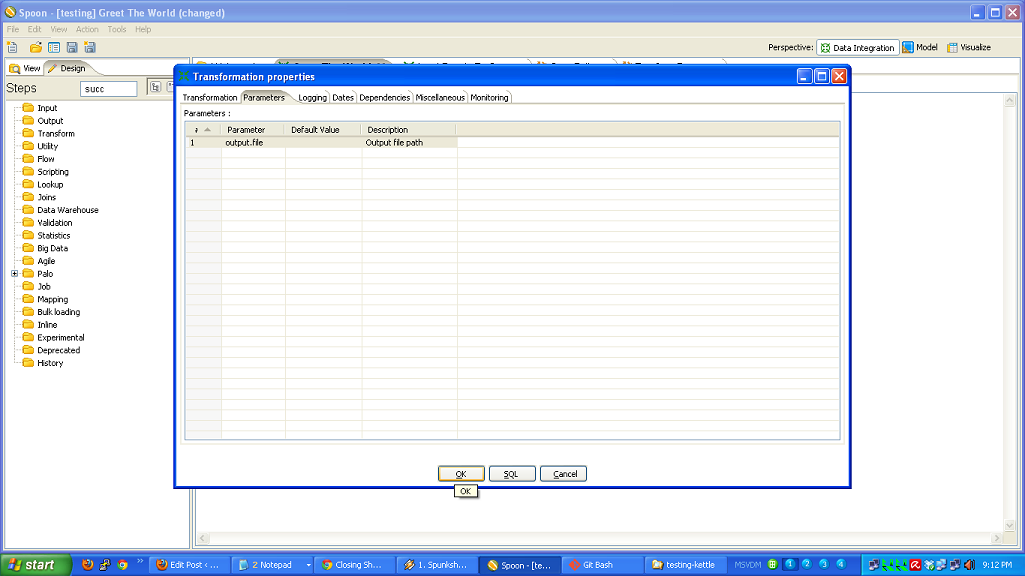
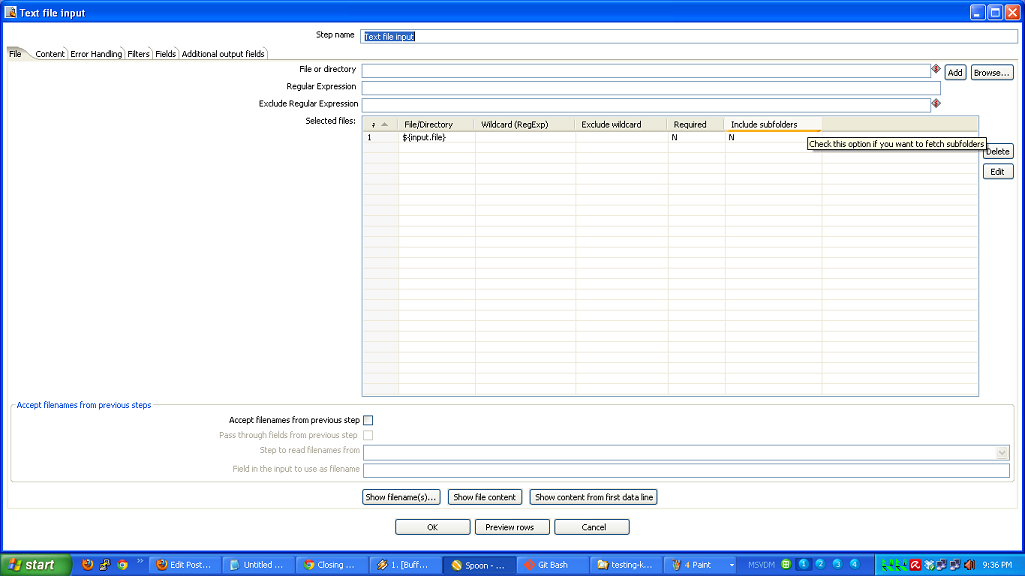
- You have to roll your own testing framework. I did.
- You have to learn another tool.
Don’t re-invent the wheel! Your data movement problem may very well be a super special snowflake, but chances are it isn’t. Every line of code you write is another you have to maintain. When you are confronted with a data movement problem, take a look at an ETL tool like Kettle and see if you can stand on the shoulders of giants. Here’s a list of open source ETL tools to evaluate.