A few weeks ago, I asked the PhoneGap google group members to fill out a simple usage survey. I was interested in versions of Cordova/PhoneGap used, as well as what device platforms were targeted. I had 30 responses over just under two weeks. Note that this survey closed on the 29th, before Cordova 3.1 was released.
Here are the results. (Some questions allowed multiple answers, so the number of responses may exceed 30.)
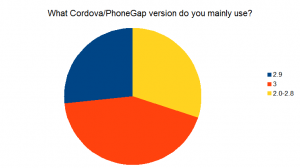
“What version of Cordova/PhoneGap do you mainly use?” A solid majority was on a modern version, either 2.9 or 3.0.
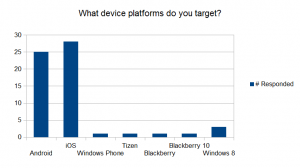
“What device platforms do you target?” The vast majority of respondents target iOS and, to a slightly lesser extent, Android. There are a smattering of other platforms being targetted.
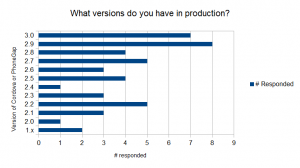
“What versions do you have in production?” Every version of the 2.x line was represented. I think this shows that upgrading PhoneGap/Cordova projects used to be a pain (and, once an app is finished, there often times is no need to revisit).
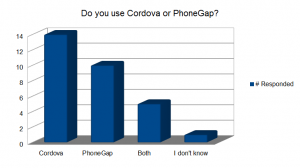
“Do you use Cordova or PhoneGap?” This is interesting to me because I think there is a lot of confusion around the difference. Most people were pretty clear.
The results of this survey was interesting to me and I hope to you as well.
