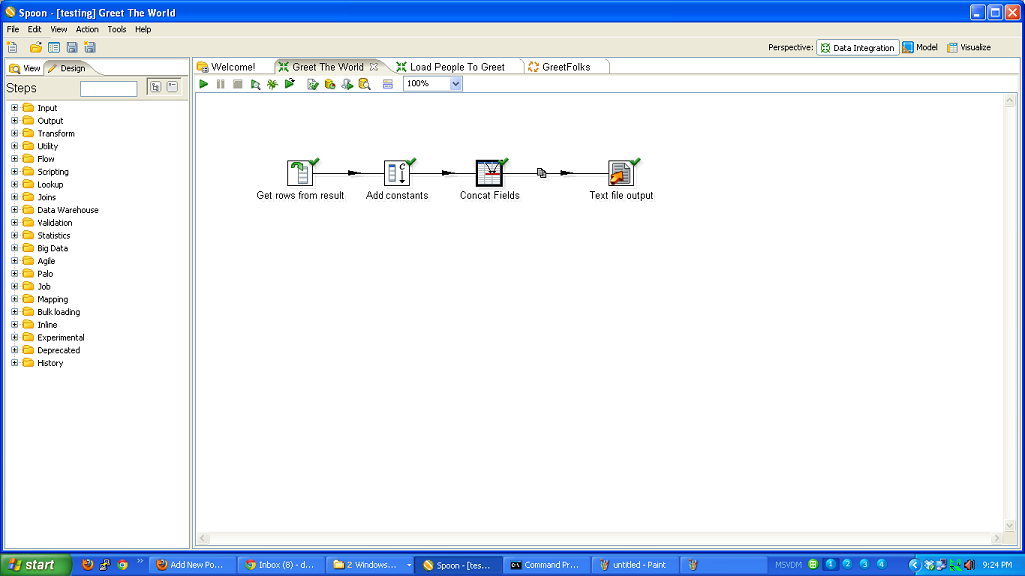
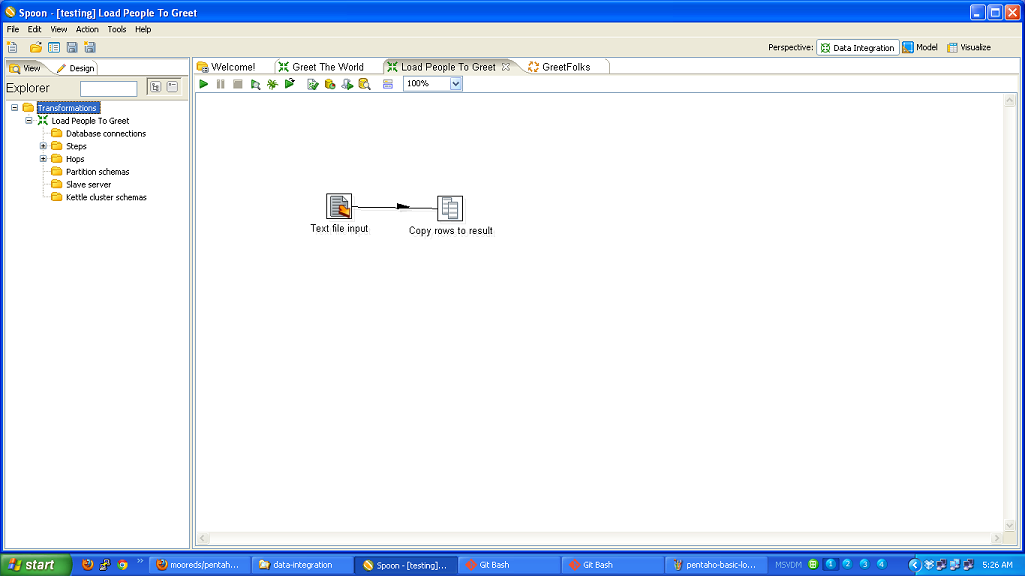
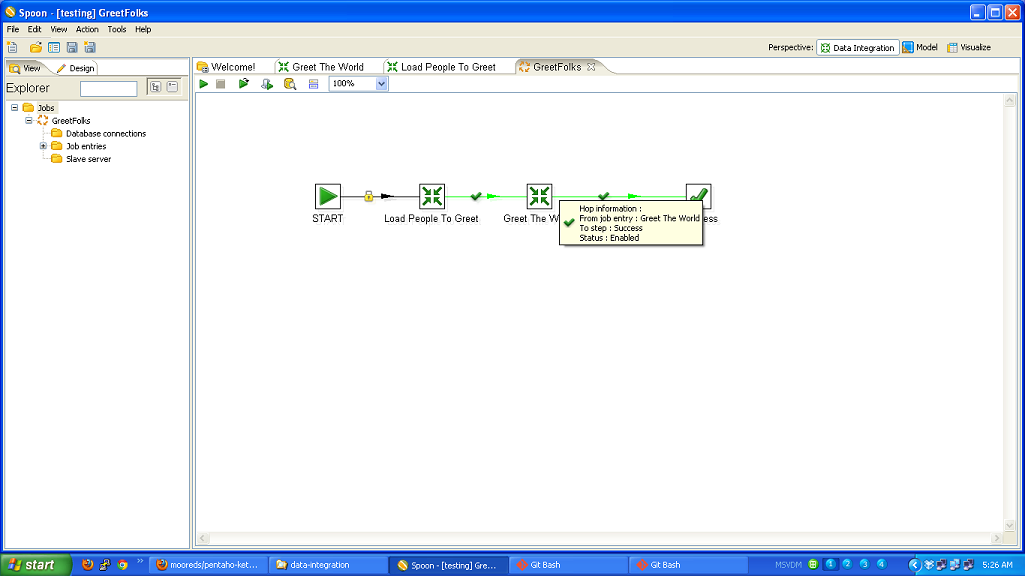
My friend and former colleague Corey Snipes has been working to get a Bootstrapper’s meetup off the ground in Denver. This is a small group (limited to 12, I believe) of people who are building products (typically software) and self funding. I believe most of the members are in the solopreneur mode (I know Corey is).
I imagine this kind of support group would be fantastic–certainly I had a similar group when I was a consultant in the past, and bouncing ideas off of others in similar situations made the struggle much easier.
I’ve not made this meetup yet because, a) I’m not sure I’m bootstrapping (and you know what, if you aren’t sure you’re bootstrapping, you aren’t bootstrapping!), b) I live in Boulder and Boulderites have a hard time leaving the Boulder Bubble, and c) Wednesdays in general are tough days for me to do anything outside of the house.
If you are a bootstrapper in the Denver area, take a look.