When you are making real time AML predictions against an endpoint, you can run the prediction code (sample code) locally. However, leveraging AWS Lambda can let you build a system that accesses predictions without any servers. This system will likely be cheaper and scale better than running on your own servers, and you can also trigger predictions on a wide variety of events without writing any polling code.
Here’s a scenario. You have a model that predicts income level based on user data, which you are going to use for marketing purposes. The user data is place on S3 by a different process at varying intervals. You want to process each record as it comes in and generate a prediction. (If you didn’t care about near real time processing, you could run a periodic batch AML job. This job could also be triggered by lambda.)
So, the plan is to set up a lambda function to monitor the S3 location and whenever a new object is added, run the prediction.
A record will obviously depend on what your model expects. For one of the the models I built for my AML video course, the record looks like this (data format and details):
22, Local-gov, 108435, Masters, 14, Married-civ-spouse, Prof-specialty, Husband, White, Male, 0, 0, 80, United-States
You will need to enable a real time endpoint for your model.
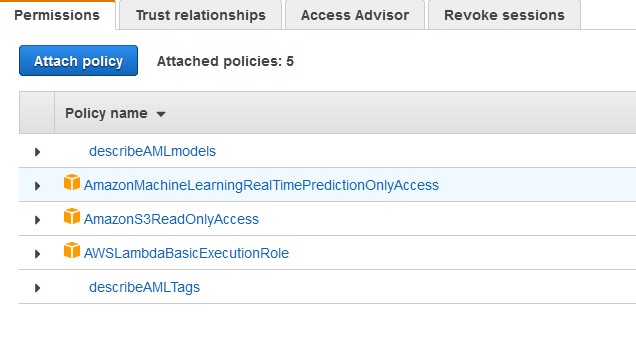
You also need to create IAM policies which allow access to cloudwatch logs, readonly access to s3, and access to the AML model, and associate all of these with an IAM role which your lambda function can assume. Here are the policies I have associated with my lambda function (the two describe policies can be found in my github repo):
You then create a lambda function which will be triggered when a new file is added to S3. Here’s a SAML file which defines the trigger (you’ll have to update the reference to the role you created and your bucket name and path). More about SAML.
Then, you need to write the lambda function which will pull the file content from S3 and run a prediction. Here’s that code. It’s similar to prediction code that you might run locally, except how it gets the value string. We read the values string from the S3 object on line 31.
This code is prototype quality only. The sample code accesses the prediction and then writes to stdout. That is fine for sample code, but in a real world scenario you’d obviously want to take further actions. Perhaps have the lambda function update a database row, add another file to S3 or call an API. You’d also want to have some error handling in case the data in the S3 file wasn’t in the format the model expected. You’d also want to lock down the S3 access allowed (the policy above allows readonly access to all S3 resources, which is not a good idea for production code).
Finally, S3 is one possible source of input, both others like SNS or Kinesis might be a better fit. You could also tie into the AWS API Gateway and leverage the features of that service, including authentication, throttling and billing. In that case, you’d want the lambda function to return the prediction value to the end user.
Using AWS Lambda to access your real time prediction AML endpoint allows you to make predictions against single records in near real time without running any infrastructure of your own.
