So, the first step in building the test harness is to create a skeleton of the transformations we will need to run. These transforms contain the business logic of your ETL process.
Pssssst. This article is part of a series. Previous posts covered:
- The benefits of automated testing for ETL jobs
- what parts of ETL processes to test
- current options and frameworks for testing Kettle
Typically, I find that my processing jobs break down into 4 parts:
- setup (typically job entries)
- loading data to a stream (extract)
- processing that data (transform)
- saving that data to a persistent datastore (load)
Often, I combine the last two steps into a single transformation.
So, for this sample project (final code is here), we will create a couple of transformations containing business logic. (All transformations are built using Spoon on Windows with Pentaho Data Integration version 4.4.0.)
The business needs to greet people appropriately, so our job will take a list of names and output that same list with a greeting customized for each person. This is the logic we are going to be testing.
First, the skeleton of the code that takes our input data and adds a greeting. This transformation is called ‘Greet The World’.
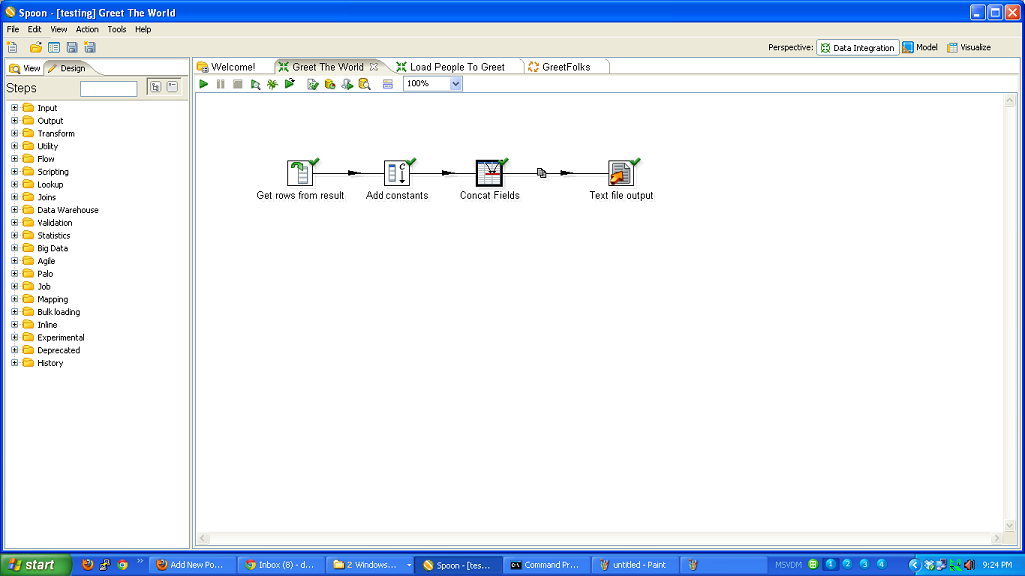
I also created a ‘Load People to Greet’ transformation that is just a text file input step and a copy rows to results step.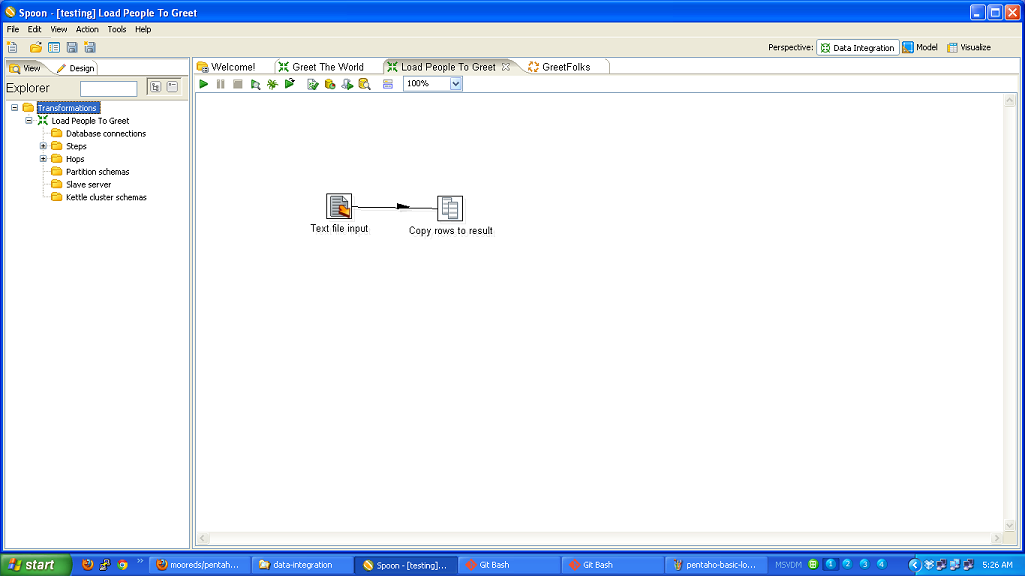
The last piece you can see in this is the ‘GreetFolks’ job which merely strings together these two transformations. This would be the real job that would be run regularly to serve the business’ needs.
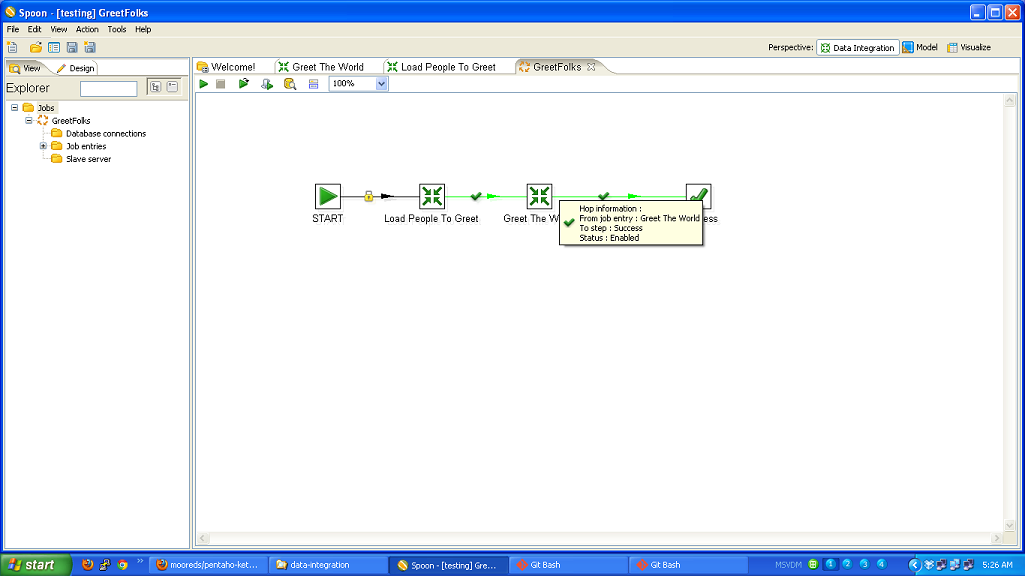
This logic is not complicated, but could grow to be quite complex. Depending on the data we are being passed in, we could grow the logic in the ‘Greet The World’ transformation to be quite complex–the variety of greetings could depend on the time of year, any special holidays happening, the gender or age or occupation of the person, etc, etc.
Astute observers may note that I didn’t write a test first. The reason for this is that getting the test harness right before you write these skeletons is hard. It’s easier to write the simplest skeleton, add a test to it, and then for all future development, right a failing test first.
As a reminder, I’ll be publishing another installment of this tutorial in a couple of days. But if you can’t wait, the full code is on github.
Signup for my infrequent emails about pentaho testing.
